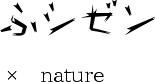
ネクストストレイン
ほぼリアルタイムで、ウイルスの感染状況を追跡しているサイト「ネクストストレイン Nextstrain(nextstrain.org)」について簡単なまとめ。
新型コロナウイルス感染症の最新状況は、「Latest data and analysis」(nCoV 2019-20)からアクセス。
他にもSeasonal Influenza(季節性インフルエンザ)、West Nile virus(西ナイル熱)、Mumps(おたふくかぜ)、Zika(ジカ熱)、Ebola(エボラ出血熱)、Dangue(デング熱)、Avian influenza(鳥インフルエンザ)、Measles(はしか)、エンテロウイルスD68、Tuberculosis(結核)などがまとめられている。
※ 結核はウイルスではなく細菌
新型コロナは、2019年12月-4月10日(現時点)の間に世界中の研究機関から集められたサンプル・データ(現時点で3513)を用いて系統樹などが描かれている。
Phylogeny 系統樹
ウイルスのサンプル間の近縁度(類似度)に応じて描かれた樹形図。
思っていた以上に頻繁に変異し続けており、もはやゴチャゴチャ。
画面左のDatasetで地域を絞ったり、Data Rangeで期間絞ったり、系統樹の枝をダブルクリックするなどして、いろいろみれる。
Datasetでアジア Asiaに絞るとアジアの国々を含まない枝葉がカットされる。
紫がチャイナで、紫がない真ん中が主に欧州・北米(下図では灰白系)。
日本からのサンプル(下図では青系)は少なめだが、真ん中にも点在。
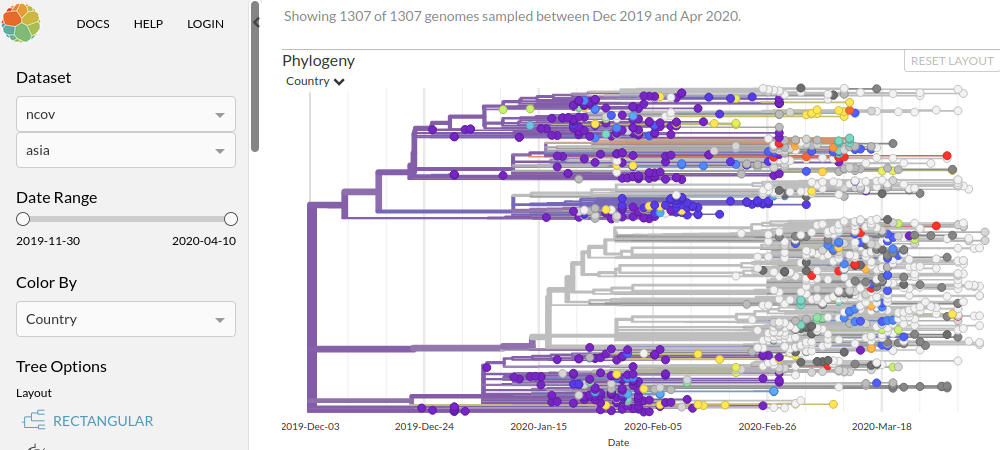
Transmissions 感染経路
感染が拡がる様子を描いた世界地図。
円のサイズはサンプル数に対応。
パンデミック世界一周で何が何だか……。
下図はDatasetでアジアに絞った場合。上の系統樹の図と色が対応。
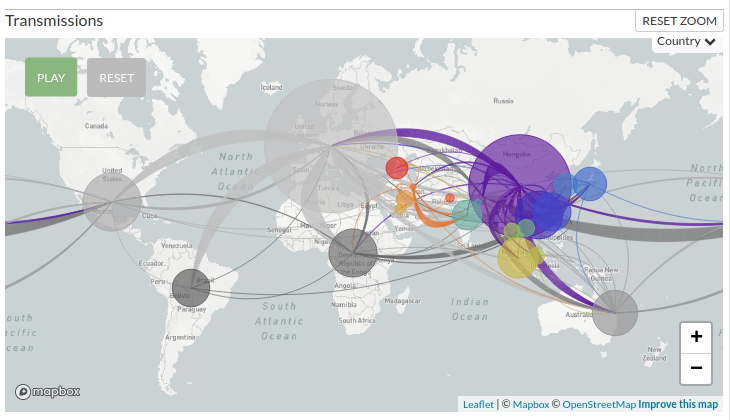
3000超のサンプルといっても全体の一部なので、図にはない感染経路がある可能性など見方には注意が必要。
Diversity [遺伝的]多様性
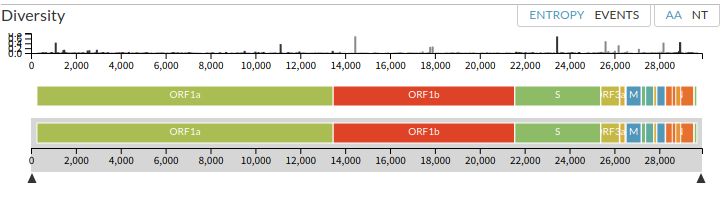
ORF1a、ORF1b、S、……が新型コロナウイルス SARS-CoV-2の遺伝子。
SARS-CoV-2のゲノムサイズは30000弱。
縦棒は塩基変動性。
突然変異を起こしている部位、その度合い。
ゲノム学習
ゲノム Genomeとは[全]遺伝情報。
ヒトを含め様々な生物のゲノムが解読されてデータは膨大。
発展著しい分野で、英語だらけなので、専門で学んだ人でないととっつきにくい。
バイオインフォマティクスとか。
学習を兼ねて整理。
ウイルスのゲノムサイズは大きくないので扱いやすそう。
※ ウイルスは生物扱いされていないが、本体はDNAかRNA
新型コロナウイルス SARS-CoV-2のゲノムは、
U.S.A. NIH NCBI(国立生物工学情報センター)のサイト(www.ncbi.nlm.nih.gov/)
からアクセスできる。
例えば”COVID”で検索(Search)して、
1月にチャイナから登録されたNC_045512というサンプルにアクセス。
※ www.ncbi.nlm.nih.gov/nuccore/NC_045512
一番下のORIGINにアルファペット4文字がずらずら並んでいる。
1 attaaaggtt tataccttcc caggtaacaa accaaccaac tttcgatctc ttgtagatct
・
・
・
4文字は、核酸(DNA/RNA)を構成するヌクレオチドの中の塩基で、
a(A):アデニン、t(T):チミン、g(G):グアニン、c(C):シトシン。
RNAの場合、TがU:ウラシル。
※ ヌクレオチド Nucleotide = リン酸 + 糖(デオキシリボース/リボース) + 塩基
SARS-CoV-2はRNAウイルス
ヌクレオチドが鎖状につながった分子がDNA/RNA。
SARS-CoV-2の(NC_045512サンプルの)ゲノムサイズは、29903 bp。
29903の塩基配列。
うち266..21555が、gene(遺伝子):ORF1ab
21563..25384がgene:S
25393..26220がgene:ORF3a
以下、E、M、ORF6、ORF7a、ORF7b、ORF8、N、ORF10
A、T、G、Cの4種の塩基は3組で1つのアミノ酸が対応し、
組み合わせによって20種の[α-]アミノ酸が対応する。
20種のアミノ酸と略号(1文字)は、遺伝子暗号表参照。
遺伝子暗号(コドン) →
例えば、
27202..27387のgene:ORF6の場合、
27181 ttgtacagta agtgacaaca gatgtttcat ctcgttgact ttcaggttac tatagcagag 27241 atattactaa ttattatgag gacttttaaa gtttccattt ggaatcttga ttacatcata 27301 aacctcataa ttaaaaattt atctaagtca ctaactgaga ataaatattc tcaattagat 27361 gaagagcaac caatggagat tgattaaacg
のatgttt~gattaaが相当し、translation(翻訳)は、
/translation="MFHLVDFQVTIAEILLIIMRTFKVSIWNLDYIINLIIKNLSKSLTENKYSQLDEEQPMEID"
atg(AUG)がメチオニン M。開始コドンは決まってM。
次のttt(UUU)はフェニルアラニン F。
taa(UAA)が終止コドン。tag(UAG)、 tga(UGA)も終始コドン。
taaの前のgat(GAU)がアスパラギン酸 D。
アミノ酸が[ペプチド]結合してproduct(製品) = 蛋白質 Proteinが合成される。
ORF6の場合、
/product=”ORF6 protein”。
Sの場合、
surface glycoprotein。
ORF1abの場合、
leader protein、nsp2、nsp3、nsp4など10以上の蛋白質。
・
・
・
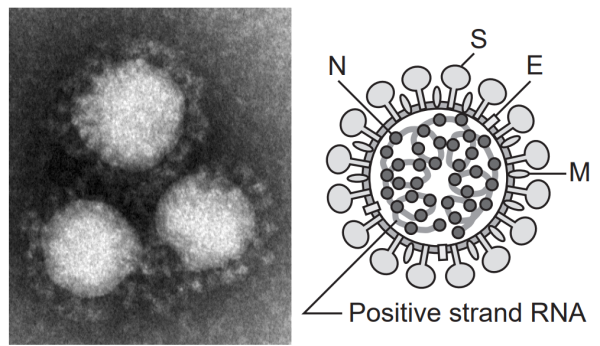
追)国立感染症研究所 「コロナウイルスとは」のページからコロナウイルスの写真・図コピー。
S:スパイク蛋白質、E:エンベロープ蛋白質、M:膜(メンブレン)蛋白質、N:ヌクレオカプシド蛋白質。
カプシドは核酸を包む殻として描かれていることが多いが、下図では核酸と絡み合っている。
突然変異を起こしている部位・領域
⇒ 遺伝的多様性
塩基配列の近縁度
⇒ 系統樹
・
・
・

